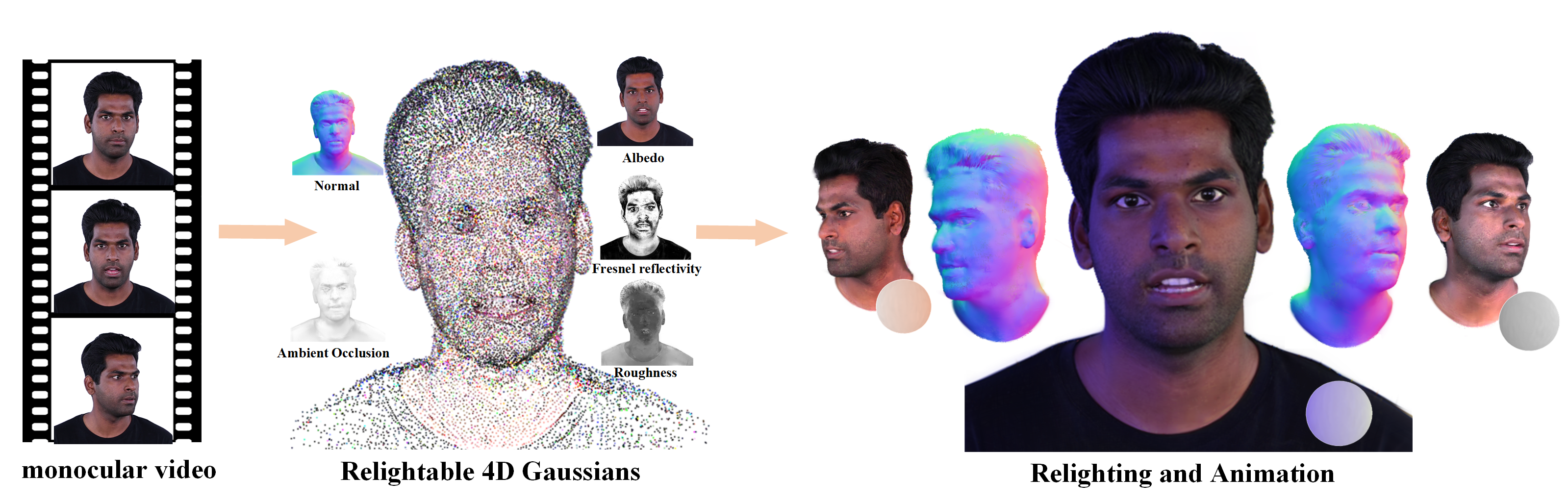
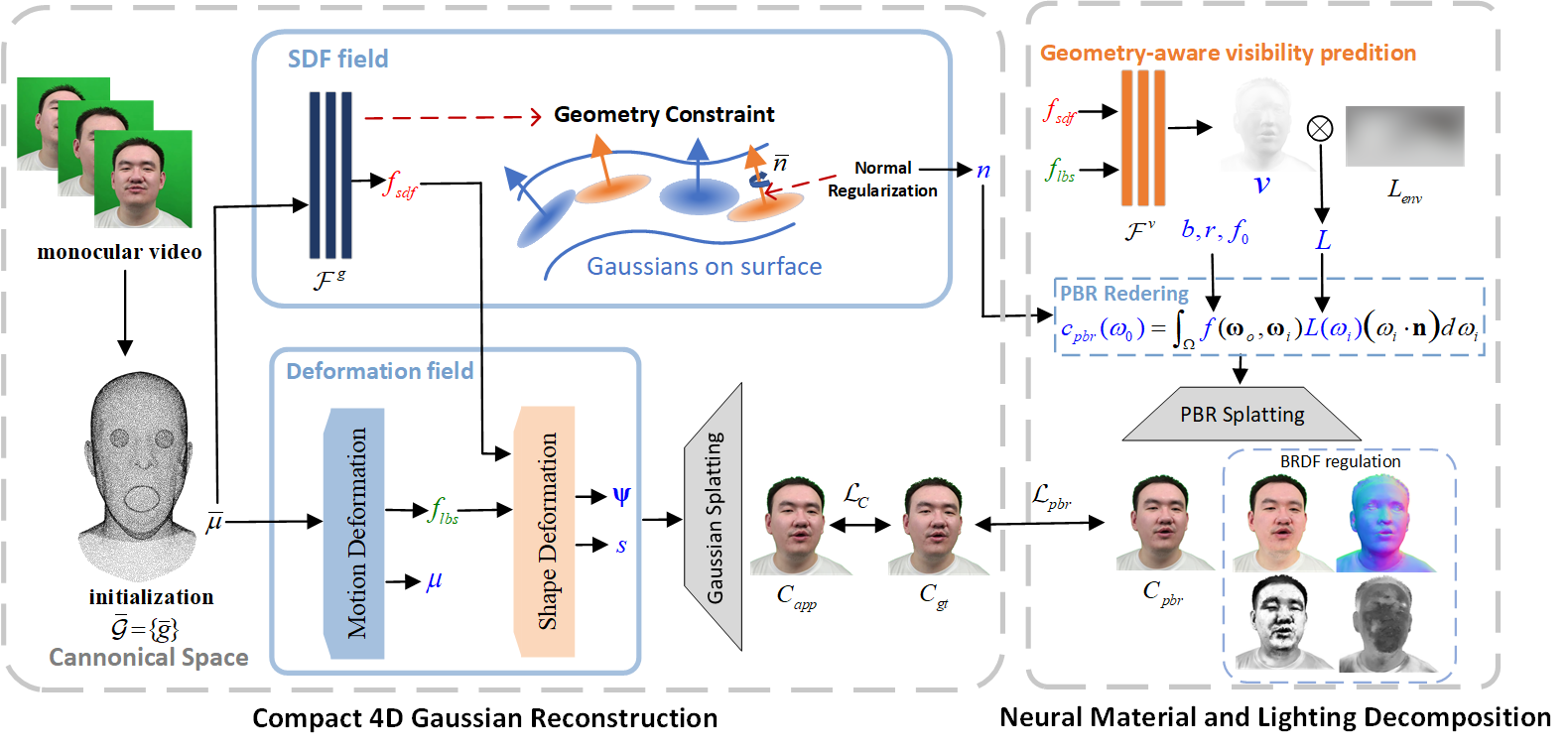
Abstract
Relightable 4D avatar reconstruction which enables high fidelity and real-time rendering continues to be a crucial but challenging problem, especially from monocular videos. Previous NeRF-based 4D avatars enable photo-realistic relighting but are too slow for rendering, while point-based or mesh-based 4D avatars are efficient but have limited rendering quality. The recent success of 3D Gaussian Splatting, i.e., 3DGS, has inspired a series of impressive 4D Gaussian avatars, however, most of which only focus on faithful appearance reconstruction but are not relightable. To address such issues, this paper proposes a new Relightable 4D Gaussian Avatar, i.e., RGAvatar, tailored for high fidelity relightable rendering from monocular videos. Our key idea is to introduce a new relightable 4D Gaussian representation, based on which we can directly perform high fidelity Physically Based Rendering, and an effective joint learning mechanism for compact 4D Gaussian reconstruction with SDF regulation and accurate materials and lighting decomposition. By comparing with previous state-of-the-art approaches, RGAvatar can significantly outperform previous approaches in relightable rendering quality and speed. To our best knowledge, RGAvatar contributes a new state-of-the-art 4D Gaussian avatar from monocular videos, which enables high fidelity relightable rendering in a quite efficient manner.